DataShop provides two main services to the learning science community:
- a central repository to secure and store research data
- a set of analysis and reporting tools
Researchers can rapidly access standard reports such as learning curves, as well as browse data using the interactive web application. To support other analyses, DataShop can export data to a tab-delimited format compatible with statistical software and other analysis packages.
Case Studies
Watch a video on how DataShop was used to discover a better knowledge component model of student learning. Read more ...
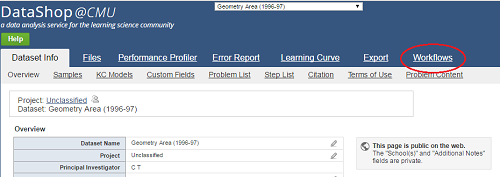
Systems with data in DataShop
Browse a list of applications and projects that have
stored data in DataShop, and try out some of the tutors and games.
Read more ...
DataShop News
Friday, January 4, 2019
LearnSphere 2.2 released!
This release features further improvements to Tigris, the online workflow authoring tool which is part of LearnSphere.
- Support for tagging workflows.
- Workflow component debugging.
- New Solution Paths visualization component.
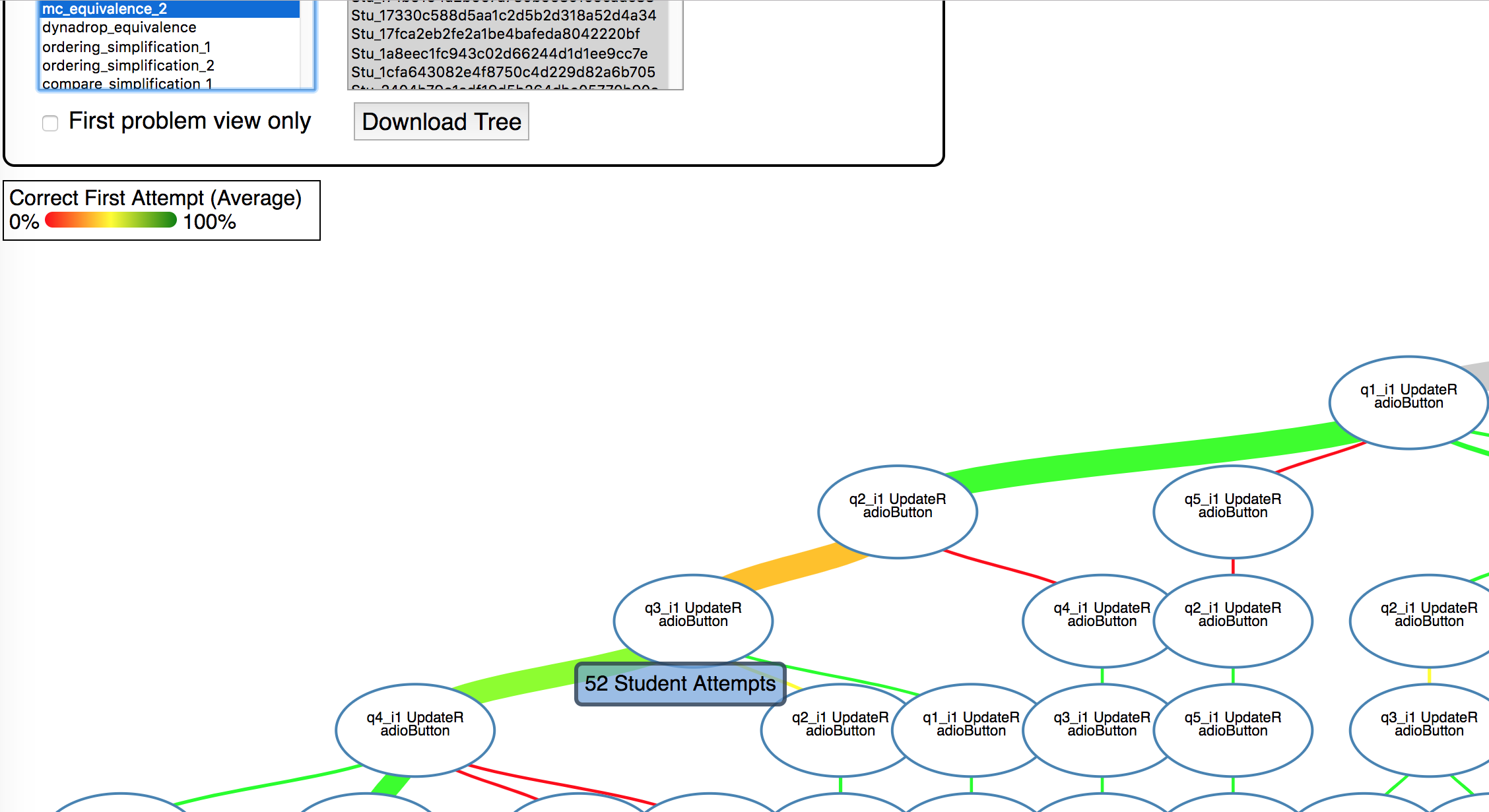
The Solution Paths component creates a visualization of the process students went through in order to solve a problem. The nodes in the graph are the steps that they encounted throughout the problem. The links show how many students took a particular path and the color of the link corresponds to the correctness of their responses from one step to the next. This component requires a DataShop transaction export input.
- Progress indicators for long-running components.
- Webservice to export Knowledge Component (KC) models.
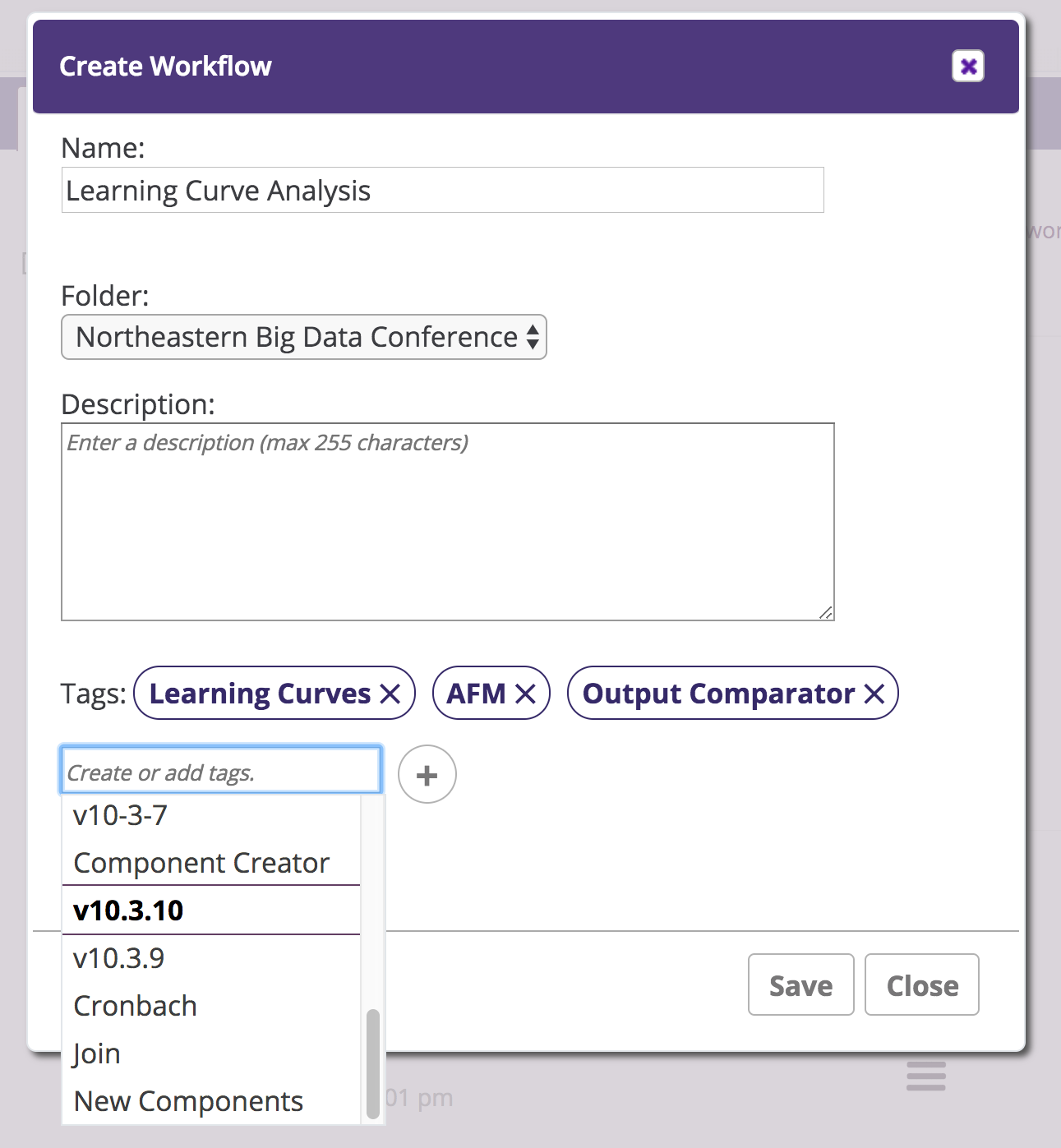
We have added support for tagging workflows and extended our search capabilities to include tags.
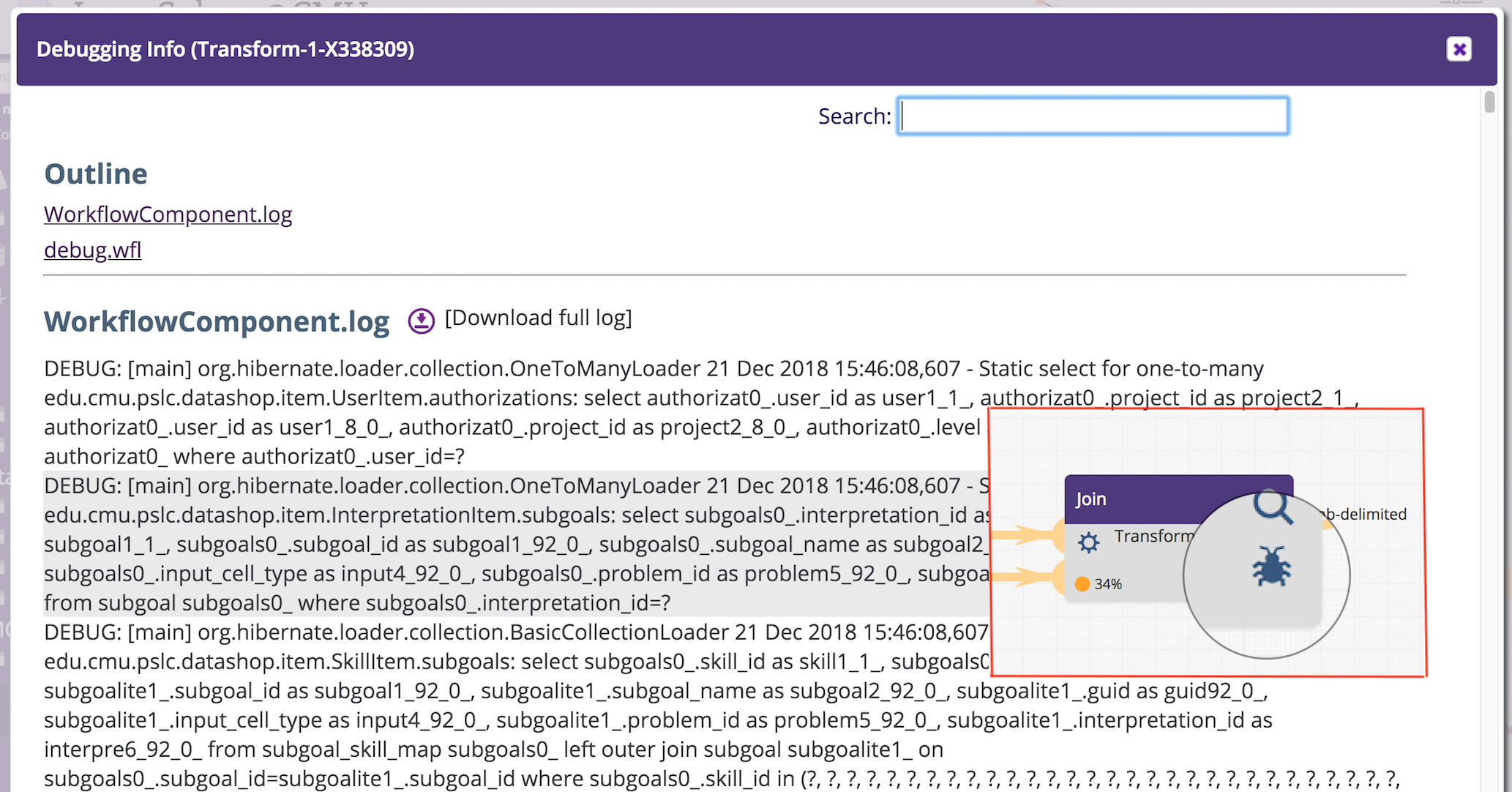
Most Tigris components were developed to generate debugging information, especially in the case of an error. This debugging output is now available to users by clicking on the bug  icon on each component. A dialog is opened with the last 500K of each debug log and a link for downloading the full log files. Note that only the owner of a workflow will see the debug icon.
icon on each component. A dialog is opened with the last 500K of each debug log and a link for downloading the full log files. Note that only the owner of a workflow will see the debug icon.

We have added infrastructure that allows component developers to annotate their code and provide progress feedback to users. Currently the Join component supports this, with plans to include it in an Aggregator component being added in the next release. Information about how to instrument your component to take advantage of this feature can be found in the "Component Progress Messages" section of our online documentation.
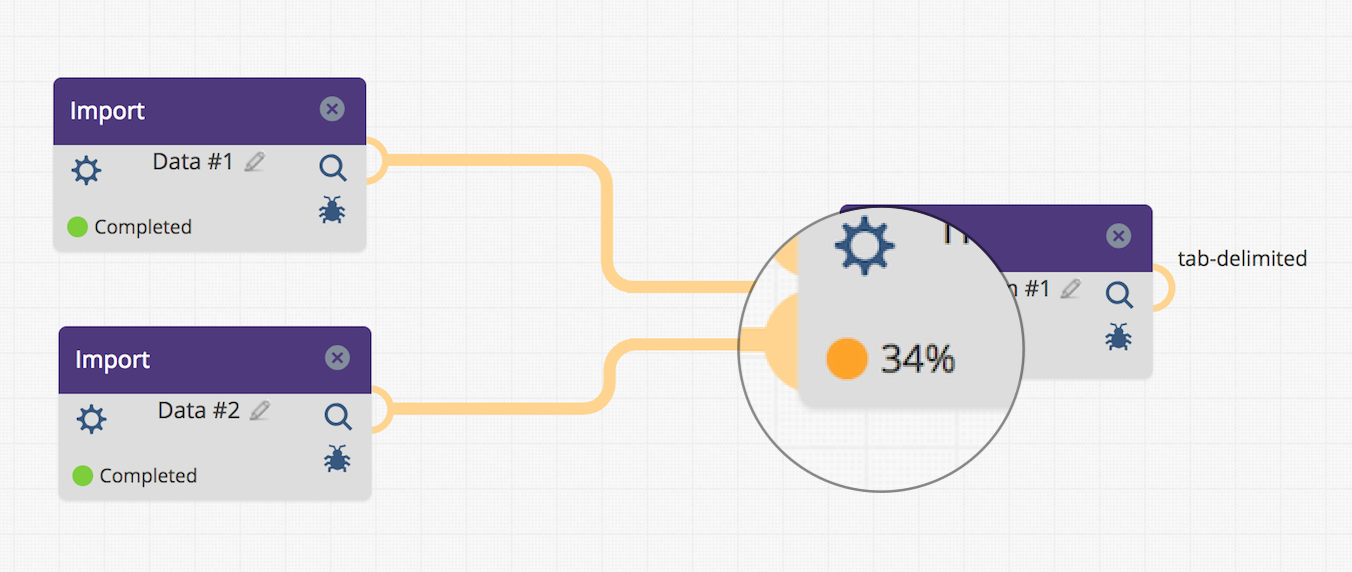
The DataShop web service was extended to support export of dataset KC models. In the near future, the OLI LearningObjective to KnowledgeComponent component will allow users to specify a DataShop dataset that they wish to generate a KC model for and have that new model generated and imported into the specified dataset. This new webservice facilitates this.
Tuesday, October 30 2018
LearnSphere 2.1 released!
This release features improvements to Tigris, the online workflow authoring tool which is part of LearnSphere.
- Redesign of workflow list to allow for better navigation.
- Advanced search of workflows.
- New visualization components.
- Private options.
- WebServices for LearnSphere.
- Ability to link a workflow to one or more datasets.
- Unique URL for each workflow gives ability to link directly to a workflow.
- In addition to the above changes, there are several component improvements.
- The R-based iAFM and Linear Modeling components have been optimized, resulting in marked performance improvements.
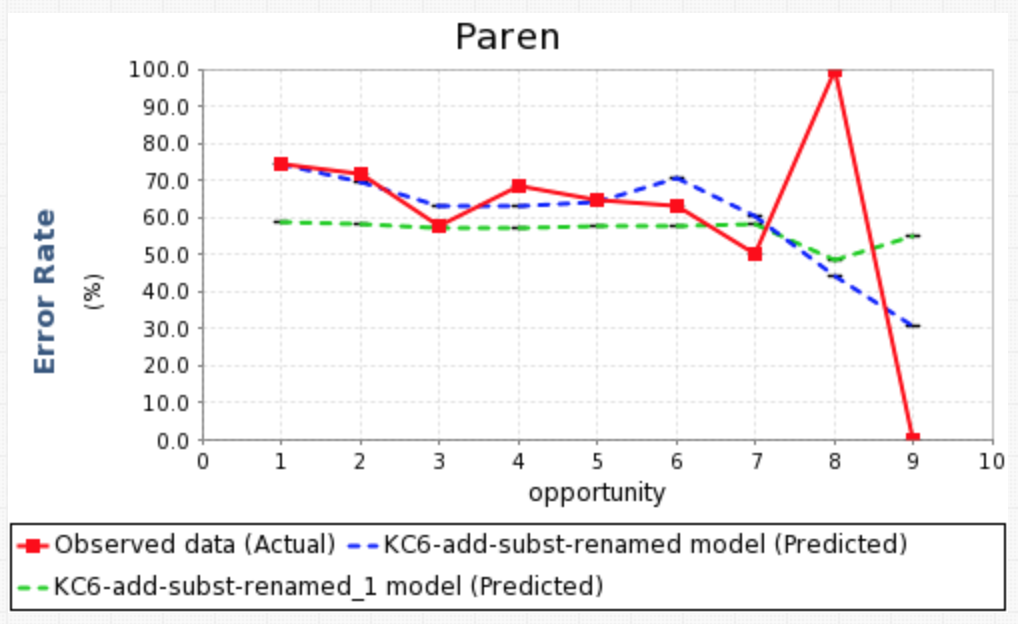
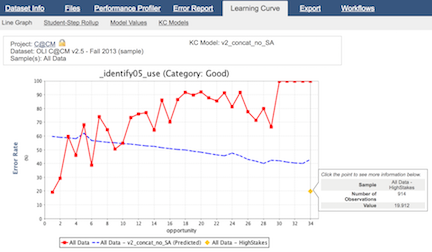
- Learning Curve categorization. A new feature, enabled by default, categorizes the learning curves (graphs of error rate over time for different KCs, or skills) generated by this visualization component into one of four categories. This can help to identify areas for improvement in the KC model or student instruction. Learn more about the categories here.
- The OutputComparator now allows for multiple matching conditions.
- There is a new component -- OLI LO to KC -- that can be used to map learning objectives for an OLI course into DataShop KC models. The component builds a KC model import for a given OLI skill model.
- The output format for the PythonAFM component is now XML, making it easier to use in the OutputComparator.
- The TextConverter component has been extended so that XML, tab-delimited and comma-separated (CSV) inputs can be converted to either tab-delimited or CSV outputs.
Returning users will recognize that the layout of the main workflows page has changed to allow for better navigation, both of their own and other's workflows. Users can now create folders in which to organize their workflows, choosing to group them by analysis methods, course or data type, for example.
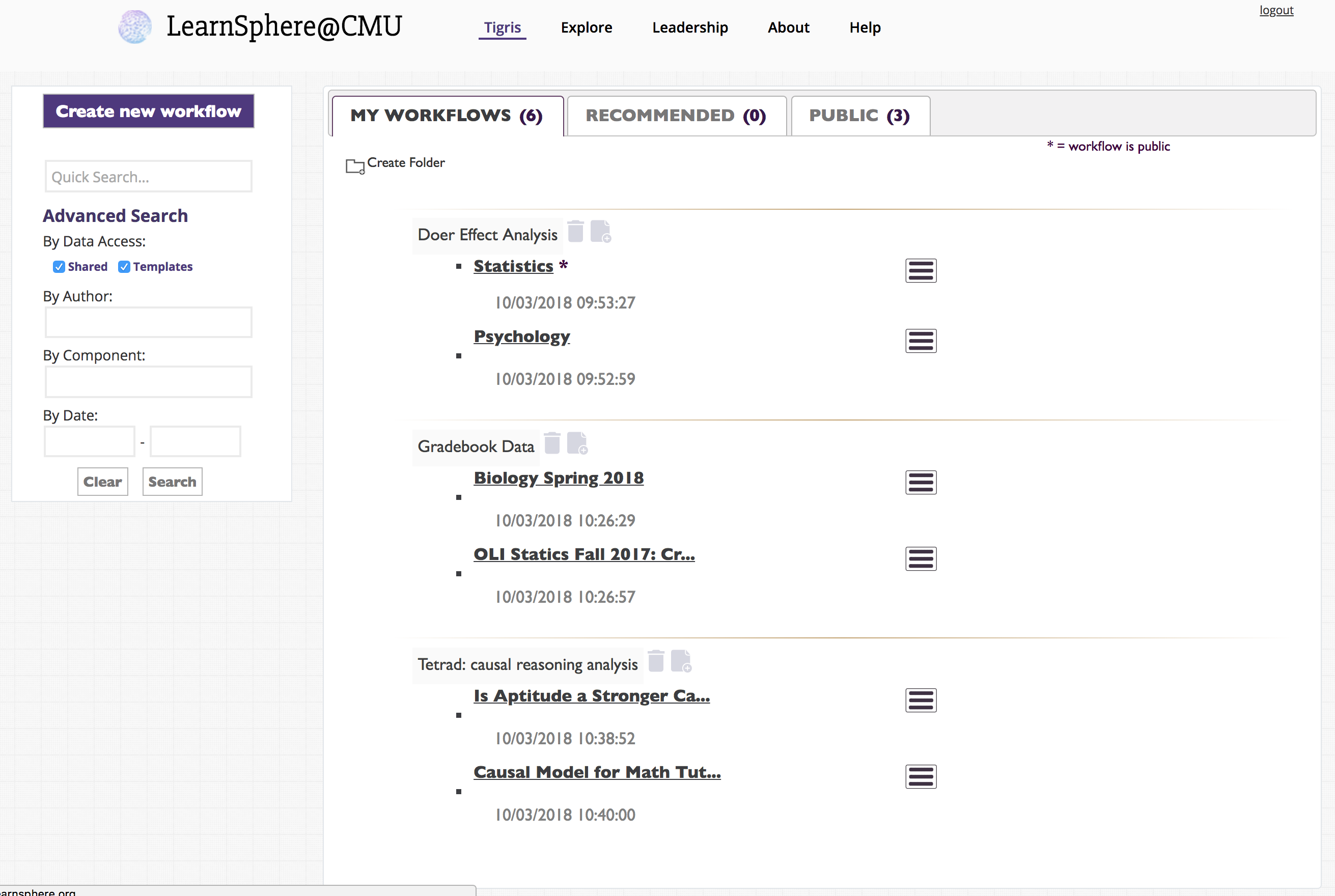
Also new to the main workflows page is an Advanced Search toolbox. The list of workflows can be filtered by owner, component, date range and access level for the data included in the workflow. The component search covers not only the component names and type (e.g., Analysis, Transform) but also workflow description, results and folders.
Four new visualization components have been added: Scatter Plot, Bar Chart, Line Graph and Histogram. Each requires a tab-delimited file as input. The file must have column headers, but can contain numeric, date, or categorical data. In the example below, a DataShop student-step export is used with the Scatter Plot component to visualize the number of times a student has seen a problem vs. the amount of time it took to complete a step.
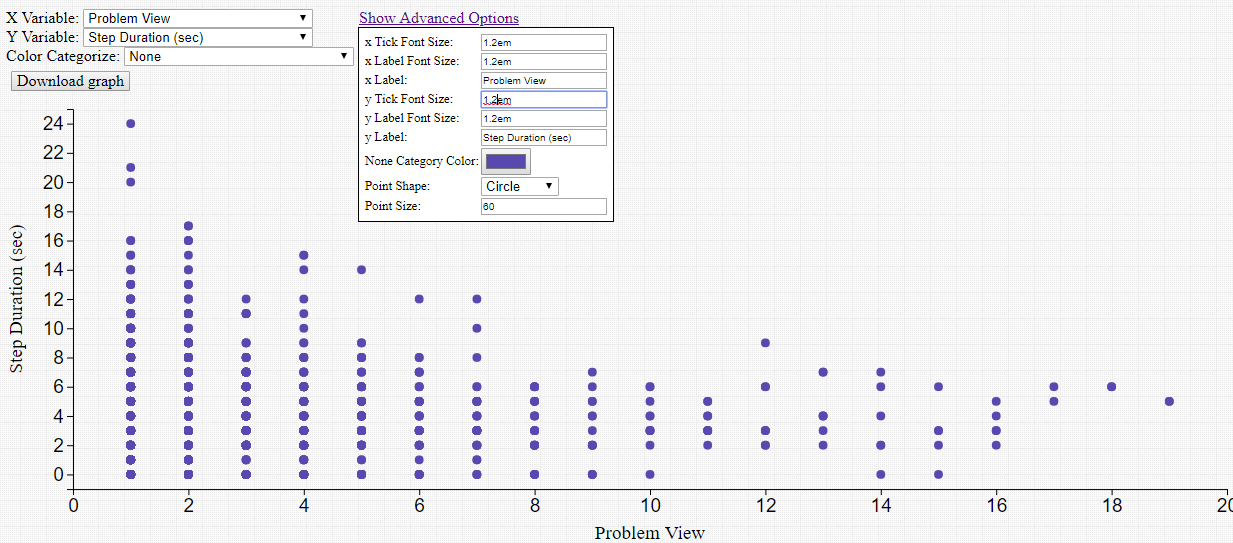
These visualization components produce dynamic content, allowing users to change both the variables that are being visualized in the output, as well as the look-and-feel of the graph, without having to re-run the entire workflow. The visualization can be downloaded as a PNG image file.
Component developers may wish to have options that contain sensitive data, e.g., login information or keys. Examples of this are the ImportXAPI and Anonymize components. For instance, in the figure below you can see that the ImportXAPI component requires a URL for the data as well as the user id and password required to access the data. With support for private options, the component author can ensure that sensitive fields such as these are visible only to the workflow owner, while other options default to 'public' and are visible to all users.
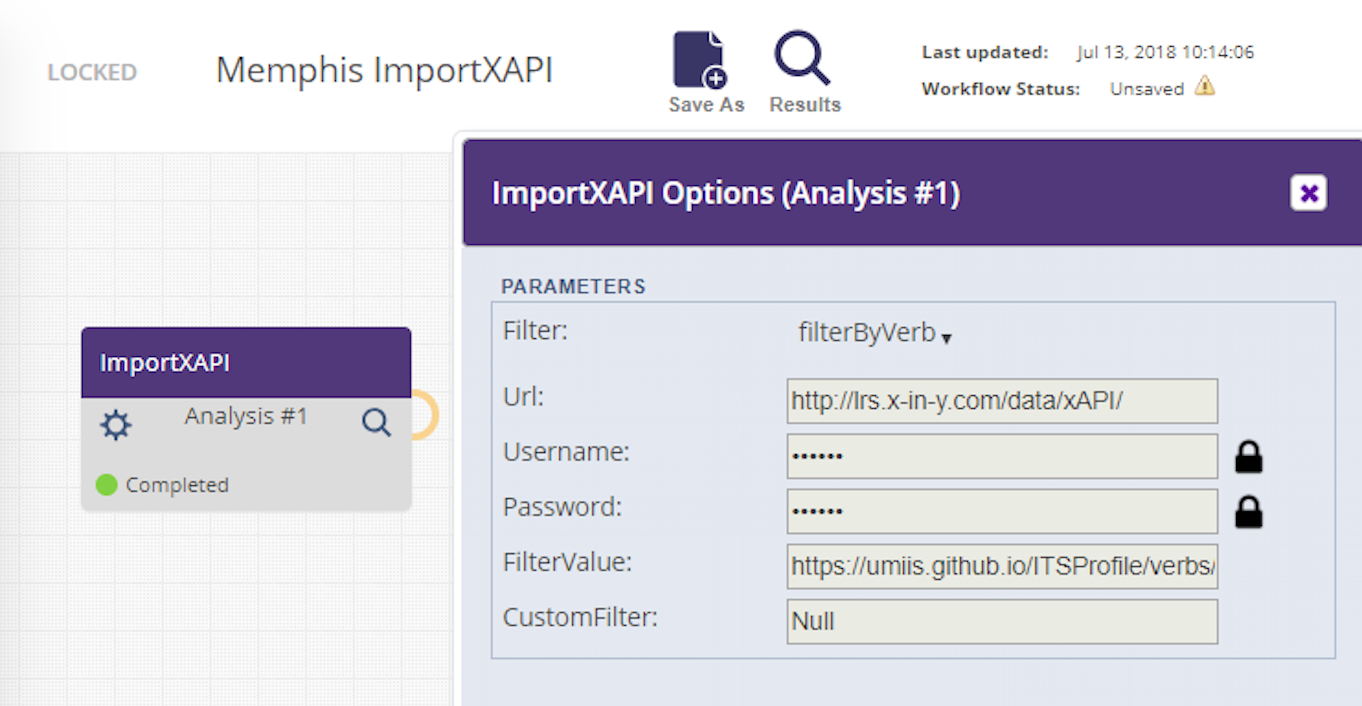
With this release you can use Web Services to programmatically retrieve LearnSphere data, including lists of workflows, as well as attributes and results for specific workflows. In the next release this functionality will be extended to allow users to create, modify and run workflows programmatically as well.
Creating a workflow from a DataShop dataset will establish a relationship between the dataset and workflow. However users may wish to link multiple datasets to a workflow and they may want to do this only after creating the workflow. There is a new "Link" icon on each workflow page that opens a dialog listing datasets that can be referenced; this is available to the workflow owner. Users viewing the workflow can click on the "datasets" link below the workflow name to see which datasets have been linked to the workflow.
To facilitate easy sharing of workflows, each workflow now has unique URL. The URL can also be bookmarked.
Friday, 13 July 2018
LearnSphere 2.0 and DataShop 10.2 released!
This release features more improvements to Tigris, an online workflow authoring tool which is part of LearnSphere. These improvements make it possible for users to better contribute data, analytics and explanations of their workflows.
- Tree structure for the list of components
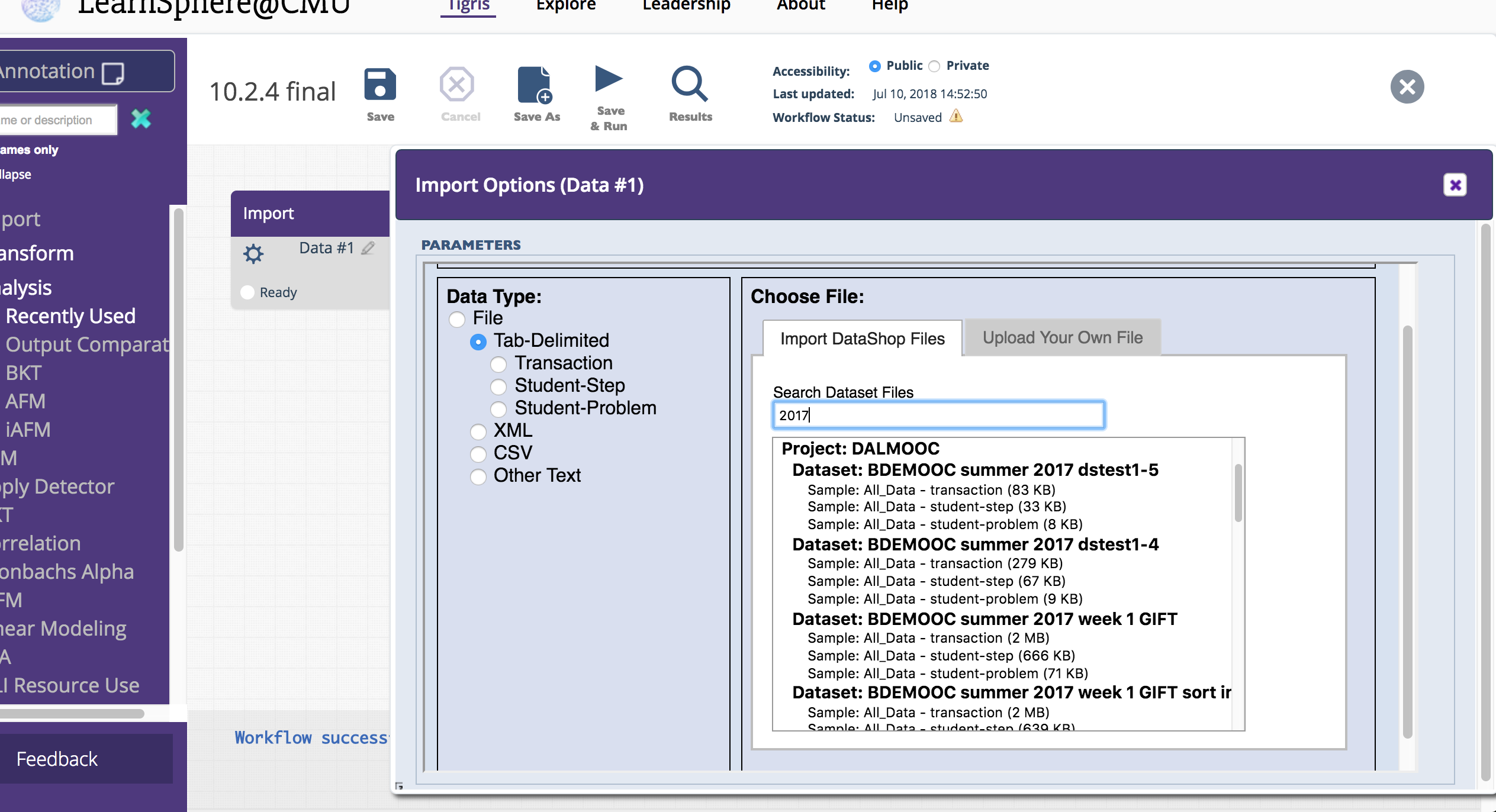
- Single Import
- Multiple files per input node
- Multiple predicted error rate curves on a single Learning Curve graph
- There are several new components available, including:
- DataStage Aggregator (Transform)
- Anonymize (Transform)
- AnalysisFTest5X2* (Analysis)
- AnalysisStudentClustering* (Analysis)
- CopyCovariate* (Transform)
- ImportXAPI* (Transform)
The Tigris components, still in the left-hand pane, are now displayed in a tree structure. The categories and the organization of the components is the same, and in addition, each category has a "Recently Used" folder. This makes it easier to find the components you most frequently use. We've also added the ability to search for components. The list will update to only show components relevant to the search term. Users can search components by name or any relevant information, e.g., the component author or the input file type.
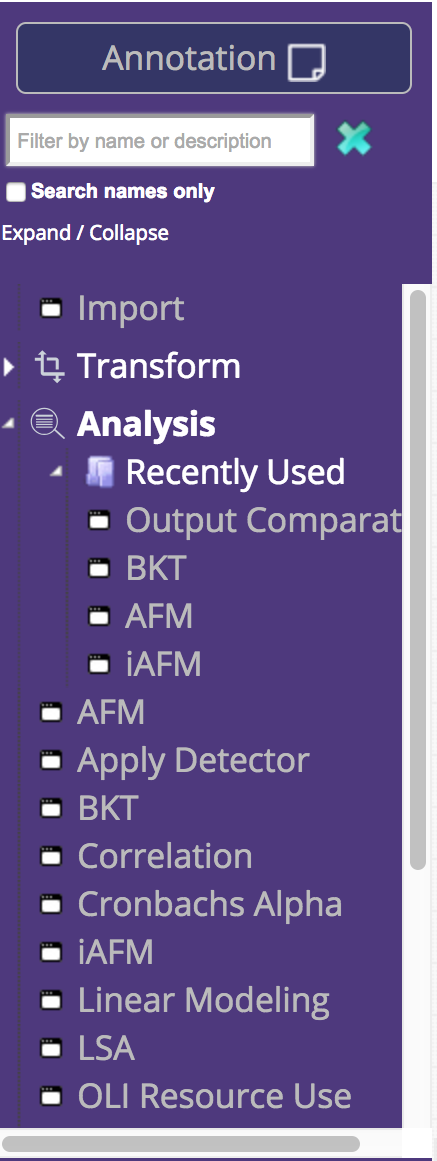
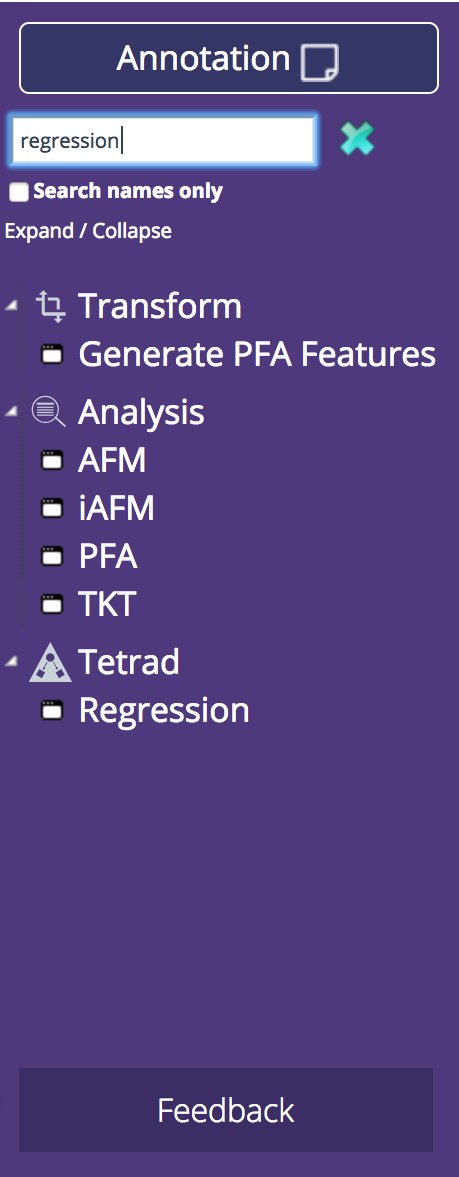
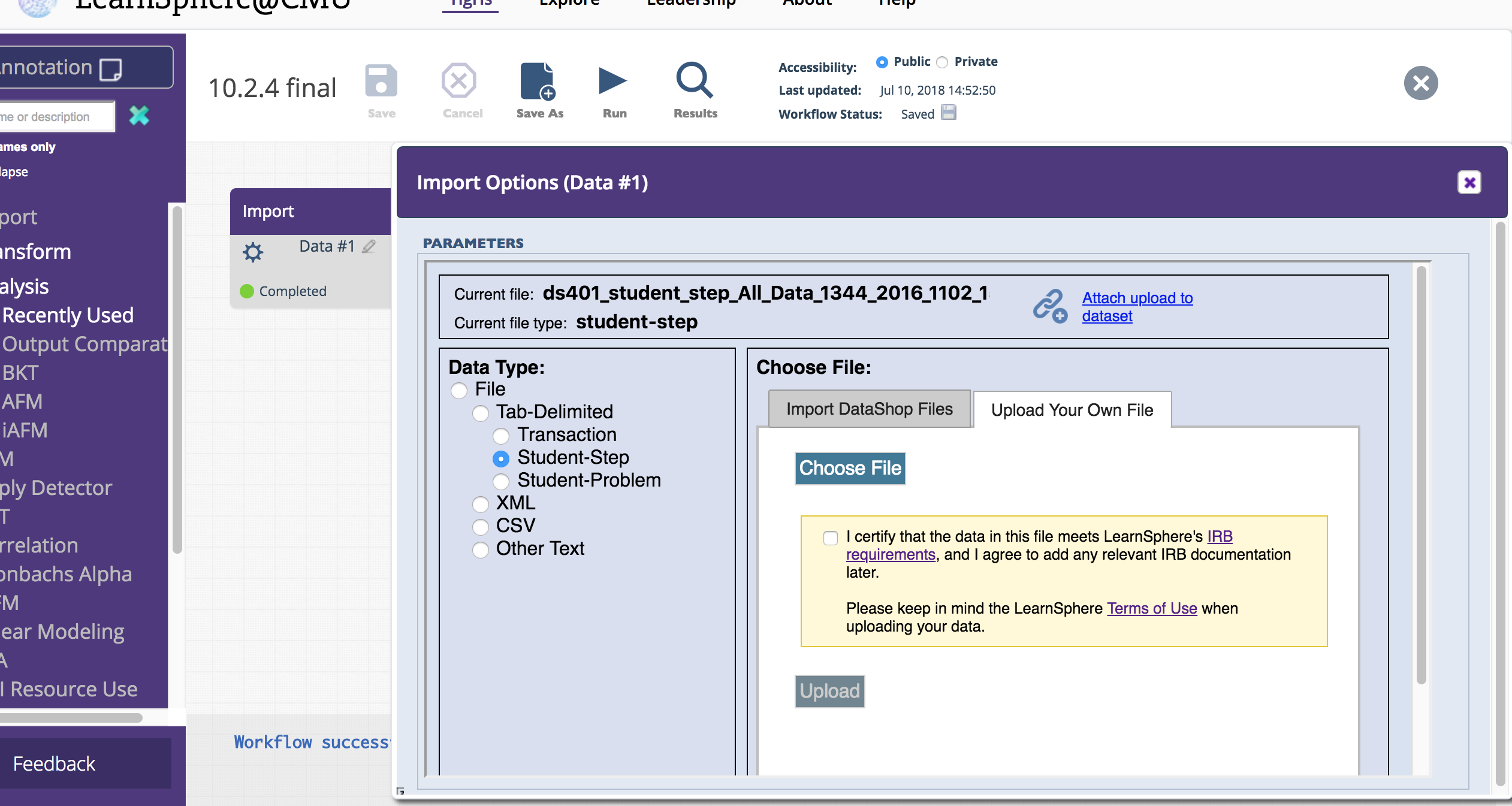
We consolidated Import functionality into a single component. Now, choosing a data file is simpler because the file type heirarchy is built into the import process. In the new Import options panel, you'll be prompted to specify your file type, which will then filter the list of available, relevant DataShop files. Alternatively, you can upload your own data file in the other tab, as shown below.
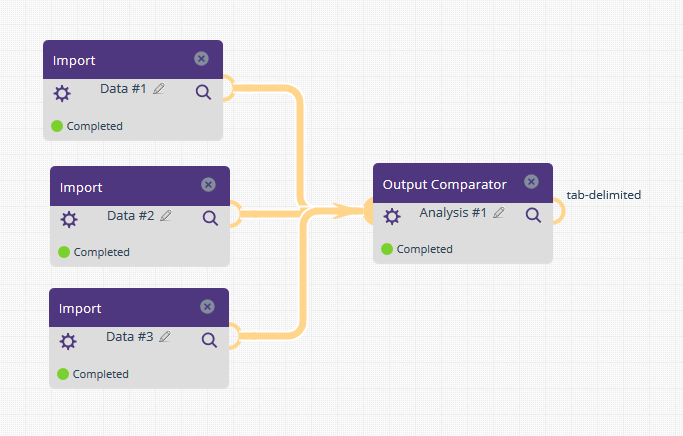
Component input nodes are no longer restricted to a single file. This means that components which analyze data across files are no longer limited by their number of input nodes. For example, the OutputComparator component, which allows for visual side-by-side comparison of variables across tab-delimited, XML or Property files, now supports an unlimited number of input files.
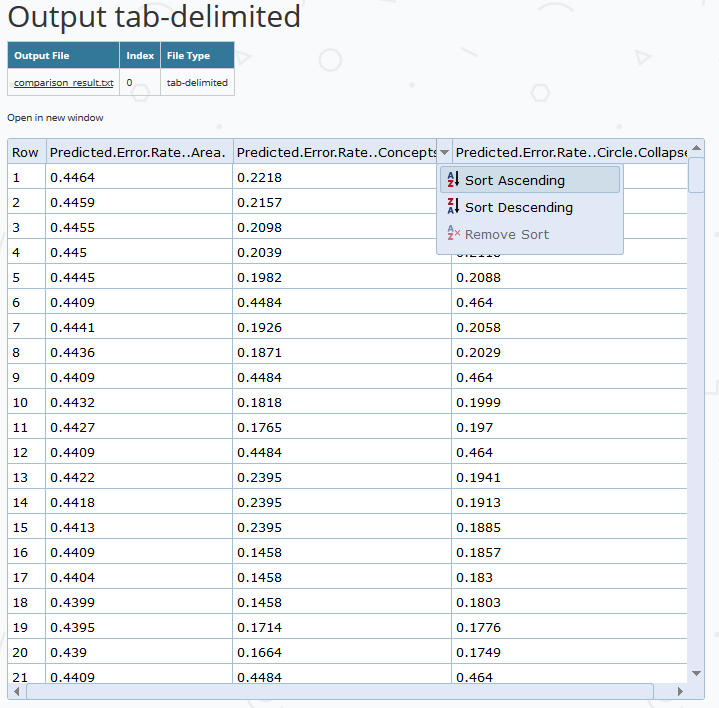
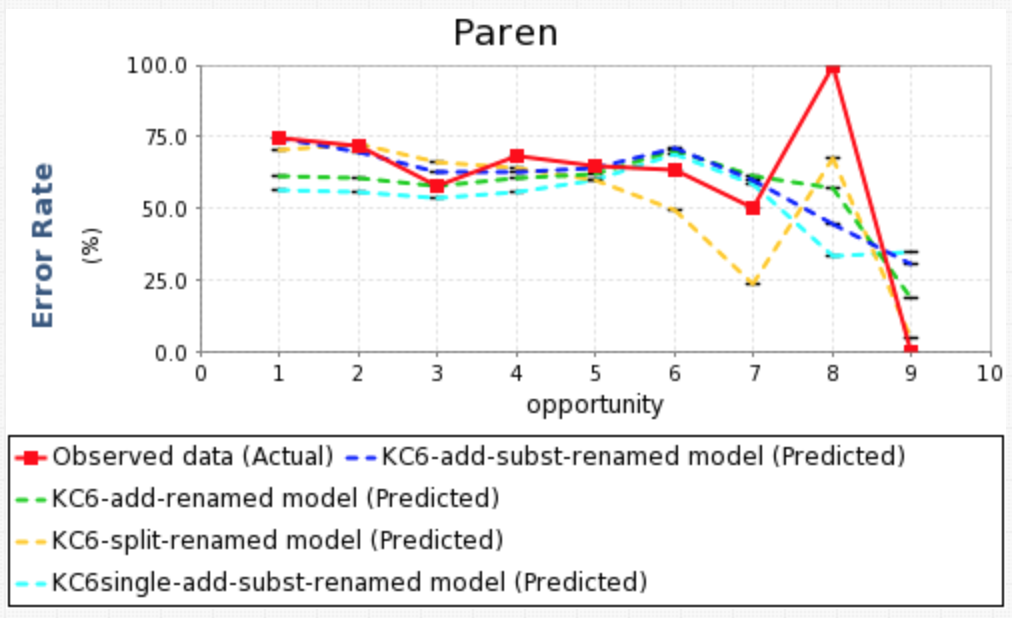
The Learning Curve component now allows users to plot multiple predicted error rate curves on a single graph. In the first example we show the predicted error rates for four different KC models, generated using the Analysis AFM component. Because this component allows for multiple input files, we can also use this component to show the predicted error rate curves across different analyses, in this case, AFM and BKT (shown in the second figure).
The DataStage Aggregator component aggregates student transaction data from DataStage, the Stanford dataset repository from online courses.
The Anonymize component allows users to securely anonymize a column in an input CSV file. The generated output will be the original input data with the specified column populated with anonymized values. The anonymous values are generated using a salt (or "key" value). This component is useful when anonymizing students across multiple files, consistently.
* These components are available at LearnSphere@Memphis.
Monday, 9 July 2018
Attention! DataShop downtime for release of v10.2
DataShop is going to be down for 2-4 hours beginning at 8:00am EST on Friday, July 13, 2018 while our servers \ are being updated with the new release.
Friday, 23 March 2018
LearnSphere 1.9 and DataShop 10.1 released!
This release features improvements to Tigris, an online workflow authoring tool which is part of LearnSphere. These improvements make it possible for users to better contribute data, analytics and explanations of their workflows.
- Workflow Component Creator
- Returning Tigris users will find many usability and performance enhancements have been made.
- We have improved processing throughput, as well as the security of Tigris workflows, by moving to a distributed architecture and off-loading component-based tasks to Amazon's Elastic Container Service.
- Tigris and DataShop now support a LinkedIn login option.
- Users can now annotate their workflows with additional information about the workflow -- the data being used, the flow itself and the results. The owner of a workflow can add sticky notes to the workflow and these annotations are available to other users viewing the workflow.
- New Analytic component functions
- The Tetrad Graph Editor component is now a graphical interface, replacing the text-based graph definition. Users can now visually define the graph.
- The Tetrad Knowledge component now has a drag-and-drop interface, allowing users to place variables in specific tiers.
- Component options with a large number of selections will now open a dialog that supports multi-select and double-click behaviors.
- There are four new components available:
- Apply Detector (Analysis)
- Output Comparator (Analysis)
- Text Converter (Transform)
- Row Remover (Transform)
We invite users to contribute their analysis tools and have written a script that can be used to create workflow components. The script can be found in our GitHub repository, along with the source code for all existing components. The component documentation includes a section about running the script. In addition, other changes make it easier to author new components: there is built-in support for processing zip files, component name and type restrictions have been relaxed, and arguments can easily be passed to custom scripts.
More information about the detectors available for use in the Apply Detector component, and papers that have been published about them, can be found here. The detectors can be used to compute particular student model variables. They are computational processes -- oftentimes machine-learned -- that track psychological and behavioral states of learners based on the transaction stream with the ITS.
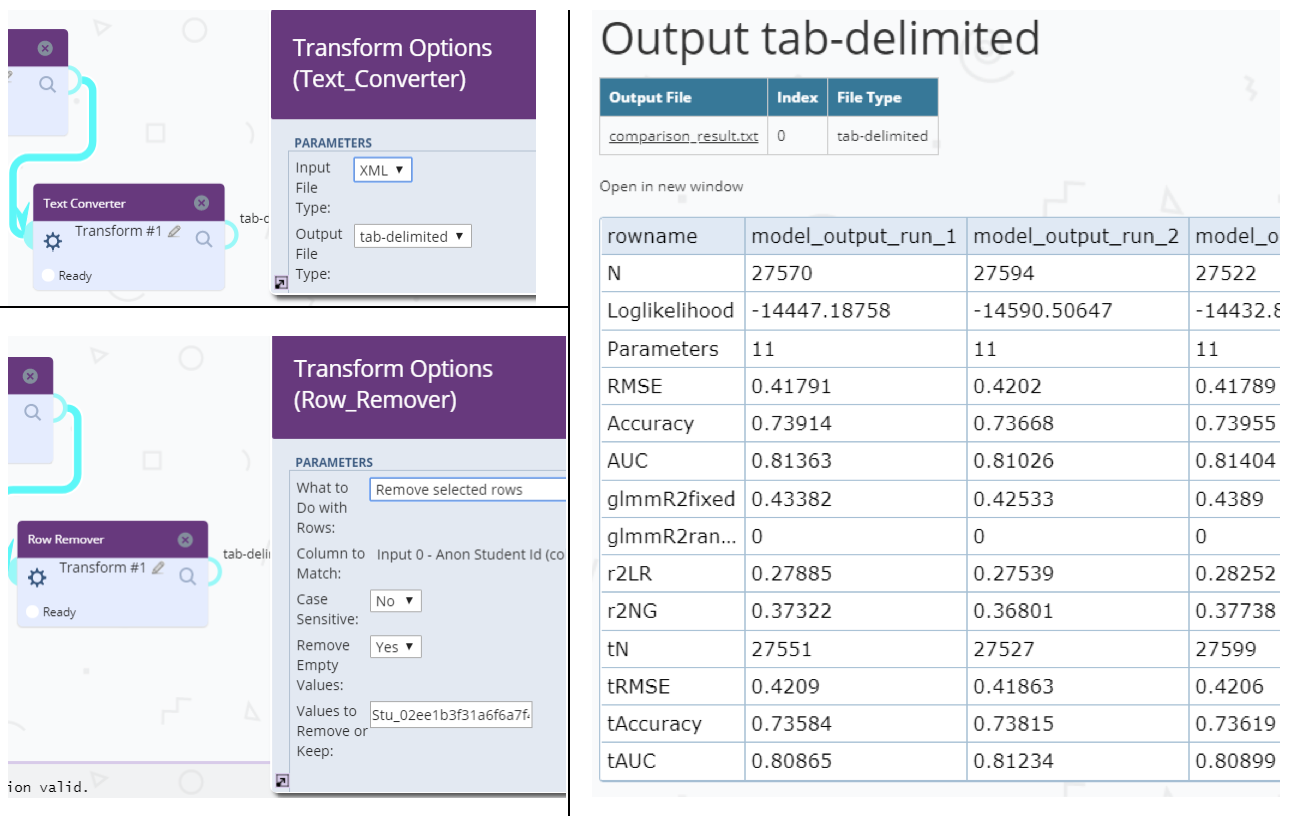
The Output Comparator provides a visual comparison of up to four input files. Supported input formats are: XML, tab-delimited and (key, value)-pair properties files. The output is a tabular display allowing for a side-by-side comparison of specified variables.
The Text Converter is used to convert XML files to a tab-delimited format, a common format for many of the analysis components in Tigris. The Row Remover allows researchers to transform a tab-delimited data source to meet certain criteria for a dataset. For example, the user can configure the component to remove rows for which values in a particular column are NULL or fall outside the acceptable range.
Saturday, 16 March 2018
Attention! DataShop downtime for release of v10.1
DataShop is going to be down for 2-4 hours beginning at 8:00am EST on Friday, March 23, 2018 while our servers are being updated with the new release.
Tuesday, 7 November 2017
DataShop 10.0 released!
With this release of DataShop we continue to extend the functionality of Tigris, the LearnSphere workflow tool, as well as enhance it's usability. There is now a 'Recommended Workflows' section at the top of the main Tigris page. This list of workflows contains those we feel best highlight the most useful features of the tool. Using the 'Save As' button, these workflows can be used as templates for users to create their own workflows. In addition, on the main page, there is a search feature that allows users to filter the workflows by name, owner or component.
A focus of this release has been adding support that facilitated the creation of many new components. For example, dynamic options are now supported. This provides component developers with option constraints that can trigger changes to the UI based on the user's selections. Dependencies can be combined in logical combinations to accomodate complex parameter sets.

The new Linear Modeling Analysis component uses this feature, allowing users to call the R functions lm, lmer, glm and glmer on a data file of their choice.
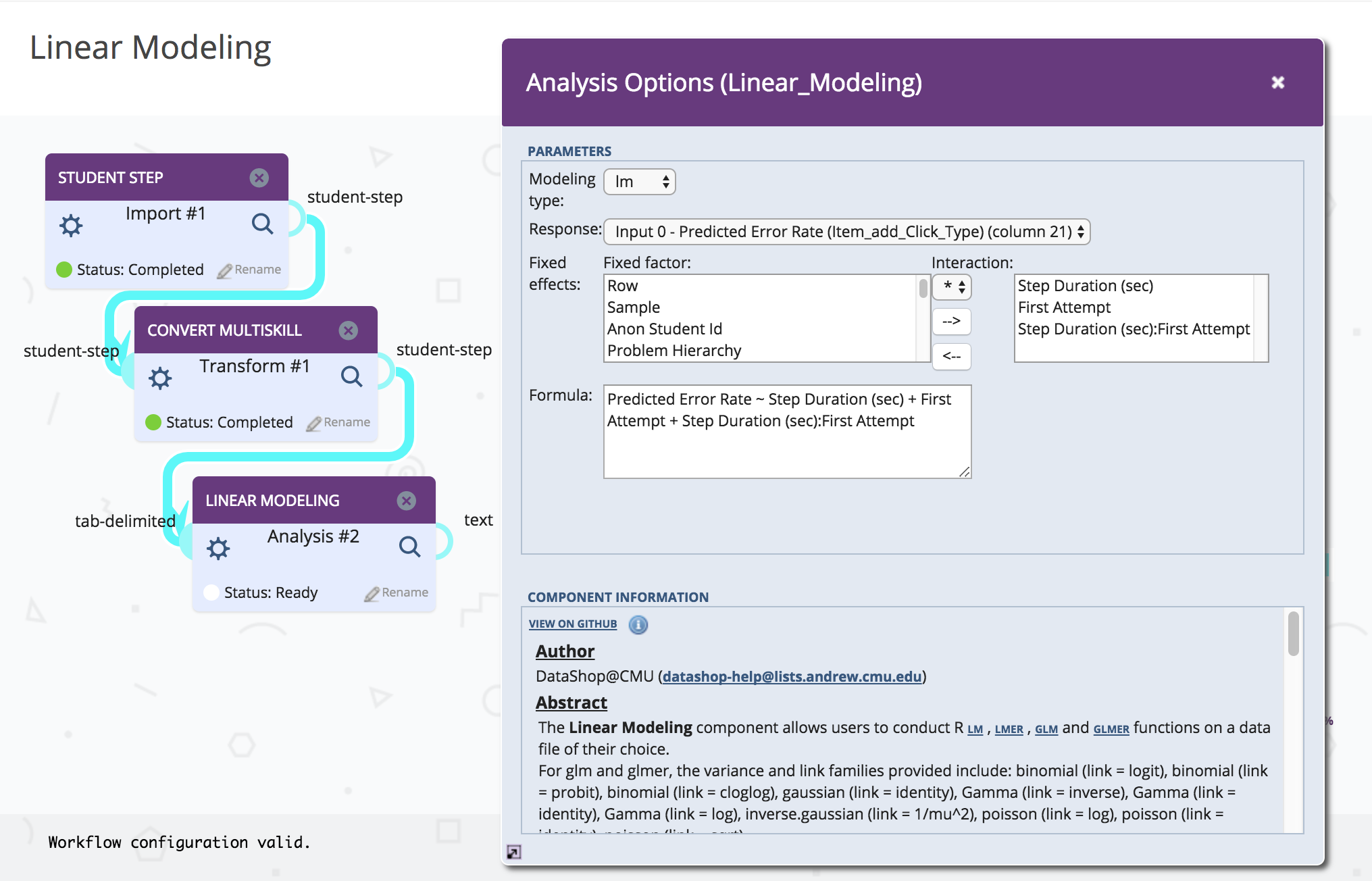
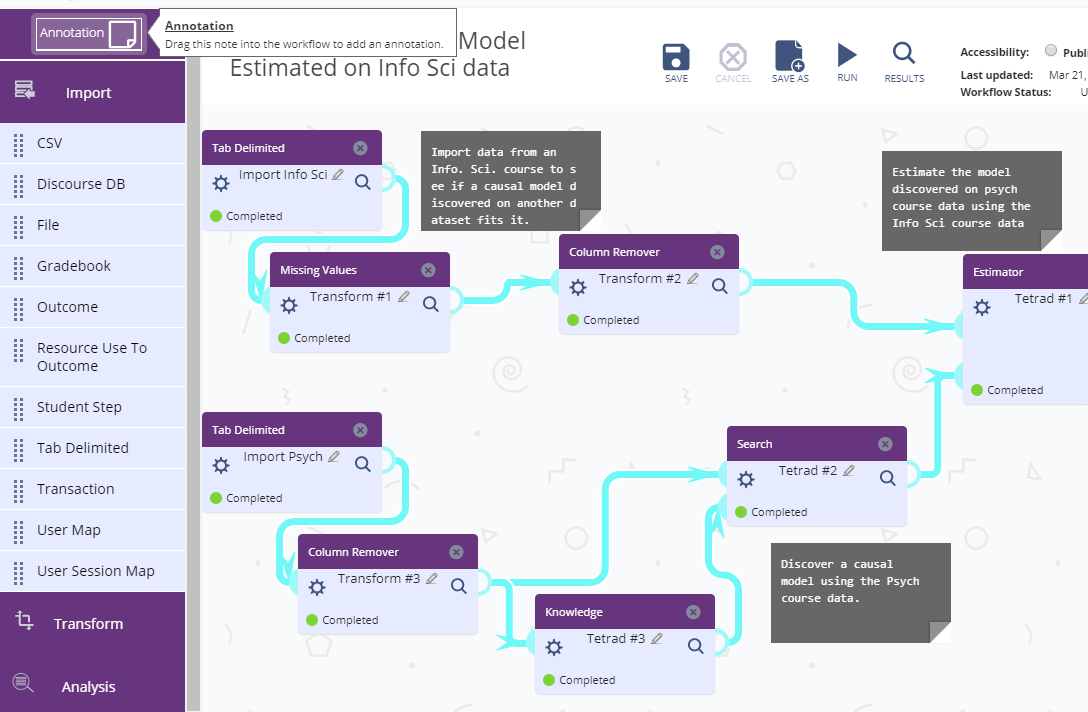
Similarly, the component definition language was extended to allow for optional inputs on components. These are common in components which generate data and also take an optional set of inputs or parameters. An example of this is the new Tetrad Graph Editor. Tetrad is a causal modeling tool that allows users to build models, simulate data from those models (or use them on real data), apply algorithms to the models and graphically display the causal relationships found.
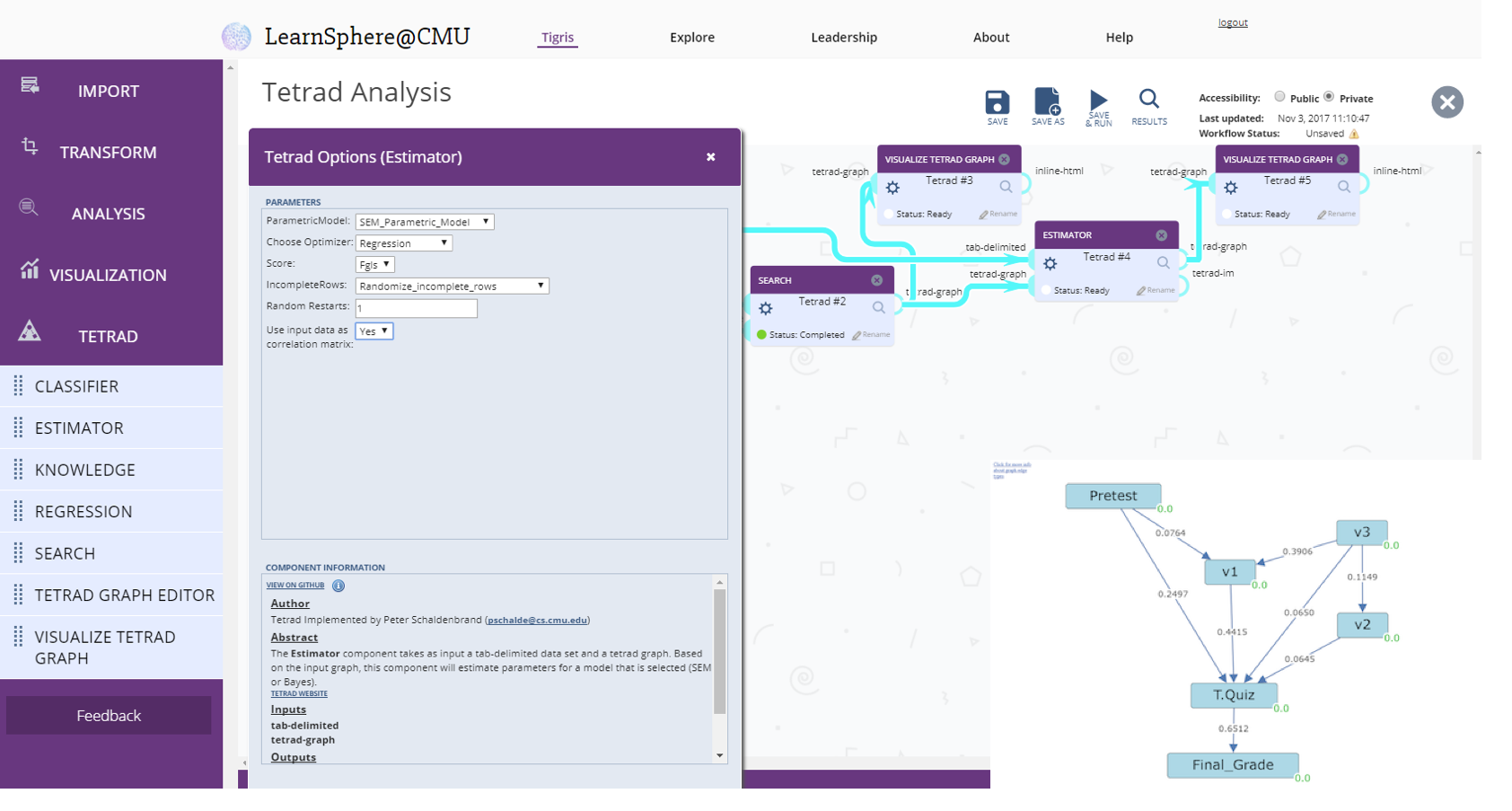
Many features of Tetrad are now supported as Tigris workflow components, making it easier for researchers to do multiple analyses on datasets that may include data from both DataShop and external sources. For example, the following Tetrad support is now available in Tigris:
- Data Conversion
- Classifier
- Estimator
- Search
- Knowledge
- Graph Editor
Following is an example workflow with several of these components. A tab-delimited data file is transformed both to filter missing values and then discretize those values before passing the data to the Search component which searches for causal explanations represented by directed graphs.
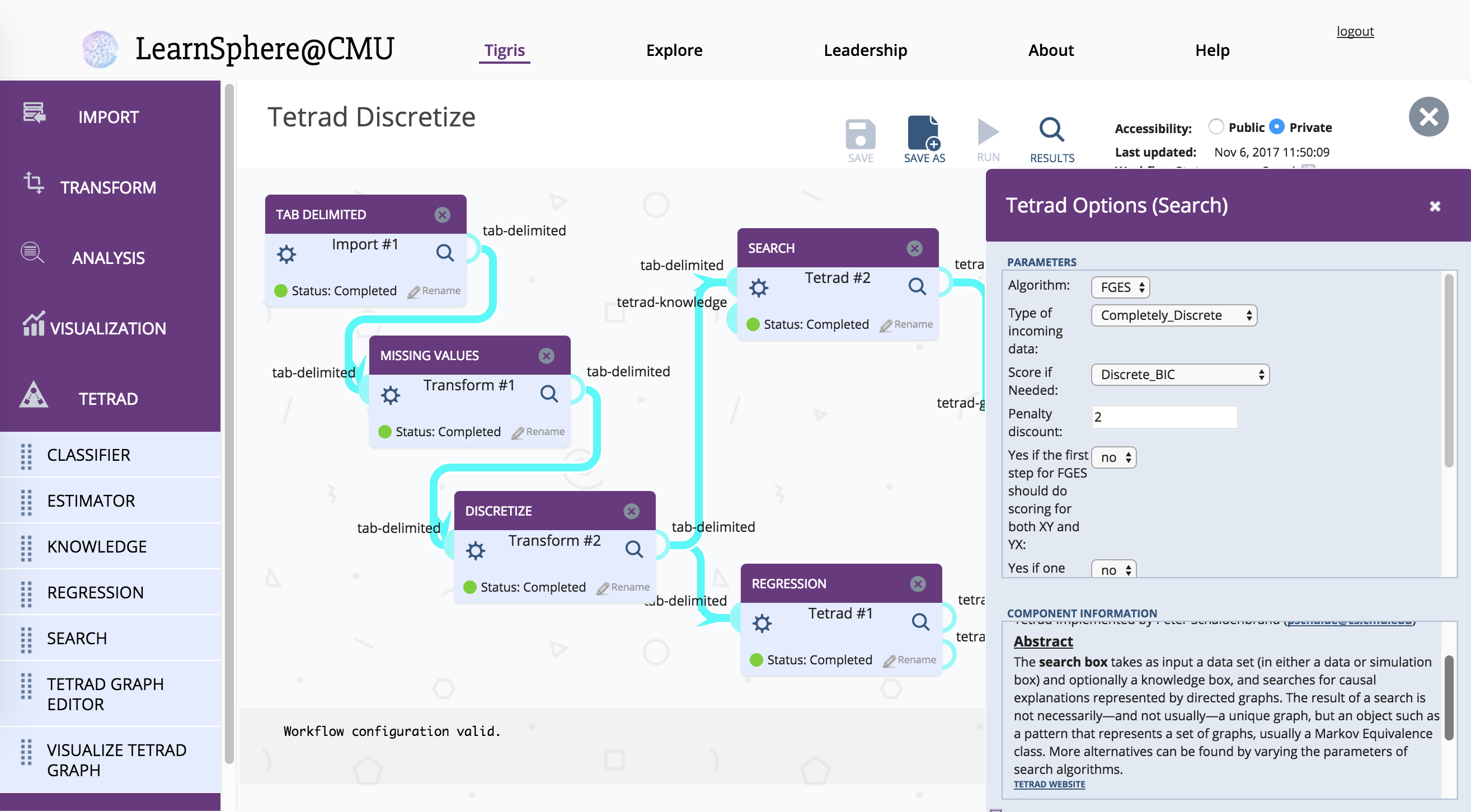
Also, two new Analysis components have been added by colleagues at LearnSphere@Memphis. They facilitate analyses of a wider variety of learning sciences data. The new modeling components are TKT (Temporal Knowledge Tracing) and LSA (Latent Semantic Analysis).
Source code for all of the LearnSphere components can be found in our GitHub repository. If you would like to add your analysis, import, transform or visualization component(s) to Tigris, please contact us for information on how to get started.
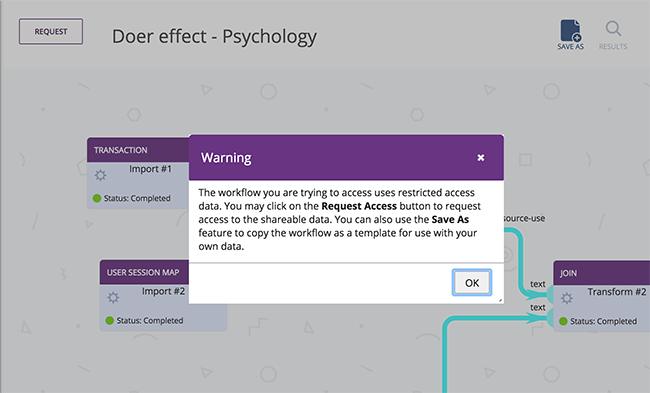
The last release added 'Request Access' support to workflows, allowing users to request access to data and results in public workflows with shareable data, but it required that all of the data used in the workflow be shareable. Workflows often use multiple data sources, though, so authorization is now enforced per-component. This means that workflows which include both private and shared data can be partially accessed by users. Results and data that are inaccessible show up as 'Locked' components.
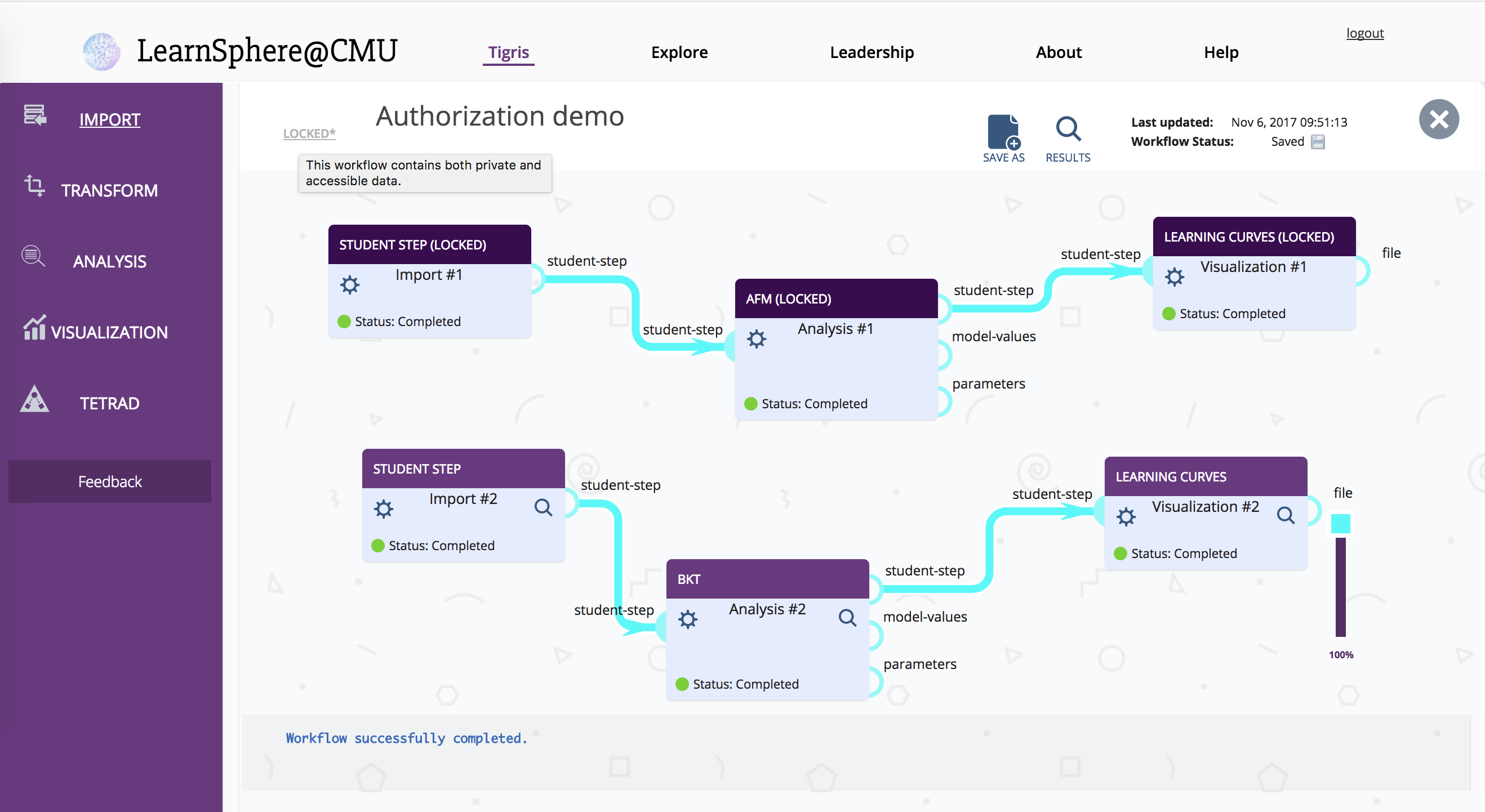
In addition to the above Tigris improvements, the following features were added to DataShop:
- The Learning Curve Model Values page now includes the 'Number of Unique Steps' and 'Number of Observations' for each skill (KC) in the selected Knowledge Component model.
- The Web Services API was extended to allow users to query and modify project authorization values.
- Tigris and DataShop both now support a GitHub login option.
Wednesday, 1 November 2017
Attention! DataShop downtime for release of v10.0
DataShop is going to be down for 2-4 hours beginning at 8:00am EST on Tuesday, November 7, 2017 while our servers are being updated with the new release.
Tuesday, 27 June 2017
DataShop 9.4 released - several Tigris enhancements and bug fixes
The latest release of DataShop includes several enhancements and bug fixes for Tigris, the LearnSphere workflow tool.
Returning users will notice a new user interface for Tigris. We have changed the look-and-feel of the tool while making numerous styling improvements and fixing several bugs.
The biggest change is the addition of Request Access support to Tigris. DataShop users are familiar with the feature that allows users to request access to projects with private, shareable datasets. This feature has been extended to Tigris; users can request access to data directly from the Workflows page.
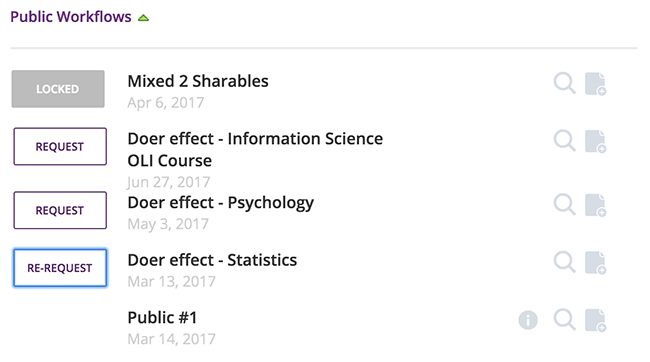
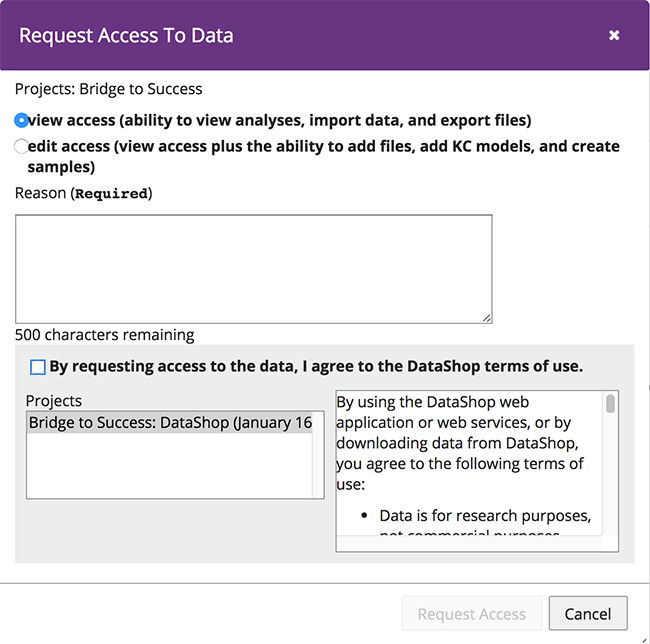
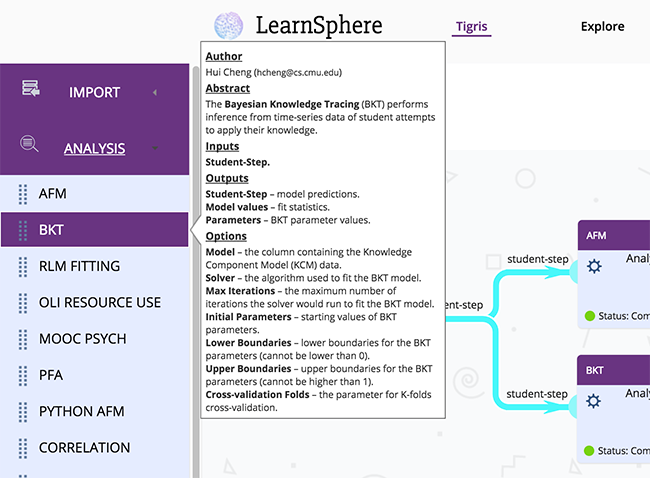
Most of the Tigris components now have tooltips which contain information on what the component does, the required input(s) and the output(s) generated as well as the component options.
The implementation code for each of the Tigris workflow components is publicly available in GitHub. If you would like to add your analysis, import, transform or visualization component to Tigris, please contact us for information on how to get started.
In addition to these Tigris improvements, the maximum allowed size for Custom Field values has been increased -- the new limit will now allow for values up to 16M in size -- and a bug in the renaming of Knowledge Component (KC) models has been fixed.
Sunday, 25 June 2017
Attention! DataShop downtime for release of v9.4
DataShop is going to be down for 2-4 hours beginning at 9:00am EST on Monday, June 26, 2017 while our server\ s are being updated with the new release.
Thursday, 16 February 2017
DataShop 9.3 released - Beta version of Tigris
The latest release of DataShop includes a Beta version of the workflow tool, now referred to as Tigris.
In order to facilitate the sharing of analyses, Tigris users can view global workflows created by other users. If the data included in a workflow is public or is attached to a dataset that the user has access to, then the workflow imports, component options and results are all accessible. If the user does not have access to the dataset they can view the workflow as a template. In both cases, users can create a copy of the workflow for use with their own data.
As part of the LearnSphere project, contributors from CMU, the University of Memphis, MIT and Stanford have been building workflow components, many of which are already available in Tigris. The latest code, with descriptions of each component, can be found in GitHub. If you would like to add your analysis, import, or visualization component to Tigris, please contact us for information on how to get started.
In addition to Tigris improvements, we have added a few enhancements and fixed several bugs:
- Users can now make a web service call to retrieve the list of data points that make up any given Learning Curve graph. The list of points can be generated for a particular skill in a specific skill model (KC Model). More about this feature can be found in the updated DataShop Public API doc.
- For OLI datasets, the Learning Curve graphs were extended to include a "high stakes error rate" data point. If you have an OLI dataset for which you'd like to see this analysis, please contact us as we will need to reaggregate your dataset to generate the necessary information.
- Long Input values were being truncated in the Error Report. This issue has been addressed.
- The Problem List page was failing to load for datasets with a very large number of problems per hierarchy, or dataset level. This has been fixed.
Friday, 10 February 2017
Attention! DataShop downtime for release of v9.3
DataShop is going to be down for 2-4 hours beginning at 8:00am EST on Thursday, February 16, 2017 while our server\ s are being updated with the new release.
Friday, 14 October 2016
DataShop 9.2 released - Alpha version of Workflow tool
The latest release of DataShop introduces an analytic workflow authoring tool. The alpha version of this tool allows users to build and run component-based process models to analyze, manipulate and visualize data.
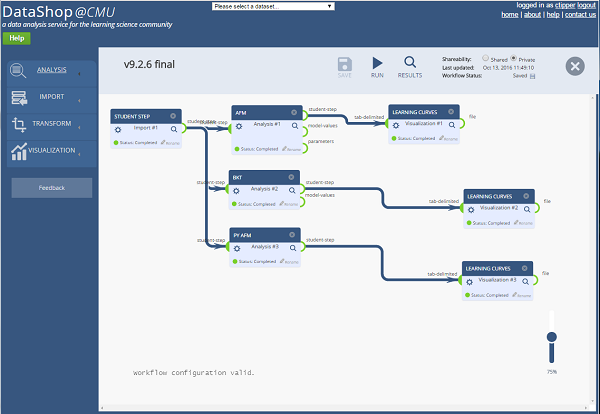
The workflow authoring tool is part of the community software infrastructure being built under the umbrella of the LearnSphere project, with partners at Stanford, MIT and the University of Memphis. The primary data flow in a workflow is a table so users are not restricted to DataShop data. The platform will provide a way to create custom analyses and interact with proprietary data formats and repositories, such as MOOCdb, DiscourseDB and DataStage.
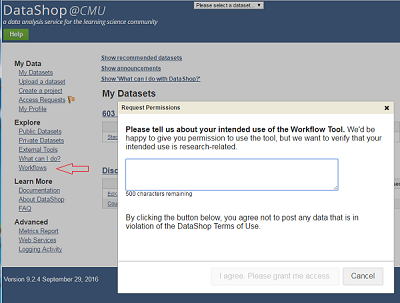
Users can request early access to the Workflow tool using the "Workflows" link in the left-hand navigation. Once granted access, this becomes a link to the "Manage Workflows" page, which is also available as a main tab on each dataset page.
Workflows are created by dragging and dropping components into the tool and making connections between components. Options can be configured for each component by clicking on the gear icon  . For example, in the import component, users can upload a file or choose from a list of dataset files for which they have access.
. For example, in the import component, users can upload a file or choose from a list of dataset files for which they have access.
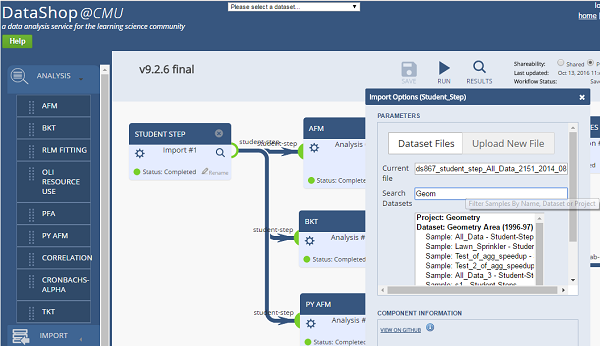
Once a workflow has been run, clicking on any component's magnifying glass icon  or the primary "Results" button will display the output of each component. A preview of the results is also available as a mouse-over on the component output nodes.
or the primary "Results" button will display the output of each component. A preview of the results is also available as a mouse-over on the component output nodes.
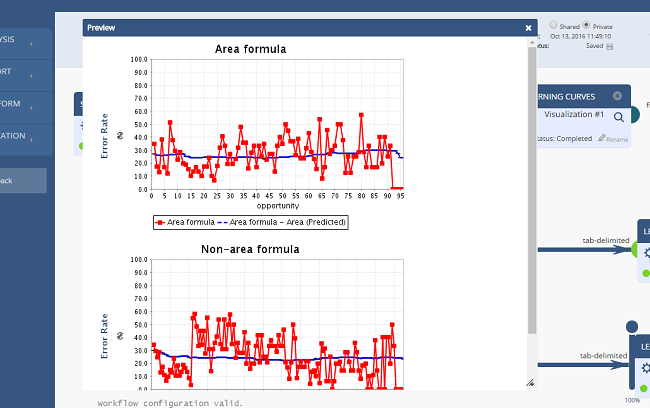
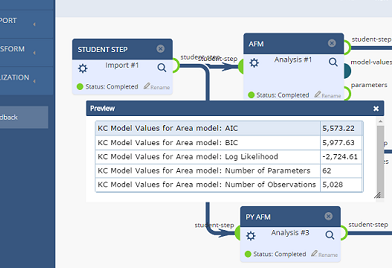
In the near future, we will invite users to contribute their own components to the Workflow tool. This feature will allow researchers to share analysis tools, for application to other datasets.
In addition to the Workflow tool, we have added a few enhancements and fixed several bugs:
- The Metrics Report now includes an "Unspecified" category for datasets without a Domain or LearnLab configured. In previous releases these datasets were not reflected in the report, causing the amount of data shown to be less than the actual data.
- KC Model exports are now being cached, allowing for faster exports of models in the same dataset.
- Users running their own DataShop instances will find that Research Goals now include links to recommended datasets and papers on the master server, DataShop@CMU.
- For Dataset Uploads, two restrictions on the upload format have been relaxed. See the Tab-delimited Format Help for details.
- If a Step Name is specified, the Selection-Action-Input is no longer required.
- Previously, if both the Problem View (PV) and Problem Start Time (PST) were specified, then the PV was recomputed based on the PST. With this release, if the two values do not agree, the PV in the upload is used.
- Users are now required to select a Domain/LearnLab designation during dataset upload.
Tuesday, 26 April 2016
DataShop 9.1 released
In the spirit of collaboration, this release focuses on integration with our LearnSphere partners, with the long-term goal of creating a community software infrastructure that supports sharing, analysis and collaboration across a wide variety of educational data. Building on DataShop and efforts by partners Stanford, MIT and the University of Memphis, LearnSphere will not only maintain a central store of metadata about what datasets exist, but also have distributed features allowing contributors to control access to their own data. The primary features in support of this collaboration are:
- DataShop now supports both Google and InCommon Federation single sign-on (SSO) options. SSO allows users to access DataShop with the same account they're already using elsewhere, e.g., your university or institution in the case of the InCommon login.
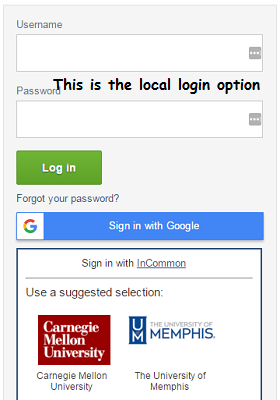
If you currently use the local login option, please contact us about migrating your account to one of the SSO options.
- Users can now upload a DiscourseDB discourse to DataShop. With support for DiscourseDB, users can view meta-data for discourses and, with appropriate access, download the database import file (MySQL dump).
- We have developed a DataShop virtual machine instance (VMI) which allows users to configure their own slave DataShop instance. The remote (slave) instance is a fully-functioning DataShop instance that runs on your server, allowing you to maintain full control over your data, while having your dataset meta-data synced with the production, or master, DataShop instance. If you are interested in having your site host a remote DataShop instance, please contact us.
In addition to the headlining features, this release also adds the following support:
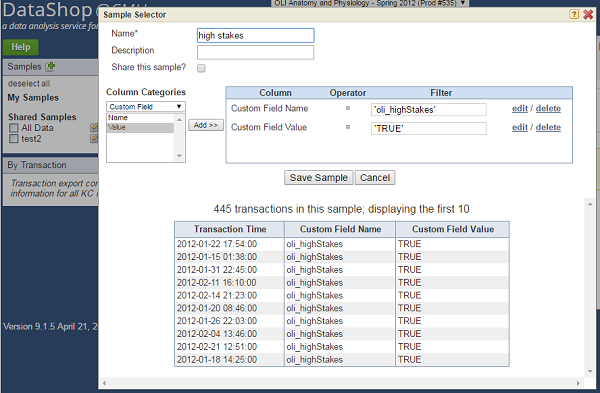
- Users can now create a sample of their dataset by filtering on Custom Fields. Sampling by the name and/or the value of the custom field is supported. This allows users to create subsets of datasets based on particular values assigned to each transaction by the tutor. For example, a step can be categorized as being high- or low-stakes for the student and the tutor can mark the relevant transactions with this information allowing those analyzing the data to filter on this information.
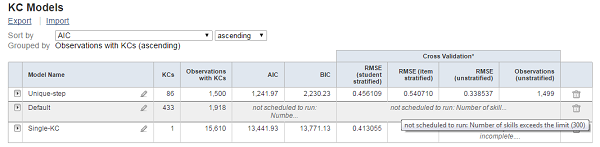
- The Additive Factors Model (AFM) is no longer limited explicitly by the number of skills in a skill model. Previously, AFM would not be run if there more than 300 skills in a model. Now, the number of students and the size of the step roll-up, as well as the number of skills, factor into the decision.
- The file size limit for dataset and file uploads was increased from 200MB to 400MB.
- The number of KC Models in a dataset is now part of the dataset summary on the project page.
Bug fixes
- Alignment errors were fixed in the KC Model Export for the case of multiple models with multiple skills.
- Clearing the Project on the Dataset Info page no longer results in a error.
- The Error Report now correctly displays HTML/XML inputs in the Answer and Feedback/Classification columns. Similarly, display errors resulting from inputs that contain mark-up, were fixed in the Exports.
Friday, 4 September 2015
DataShop 9.0 released
With the latest release of DataShop, our focus was on fixing bugs and enhancing a few existing features.
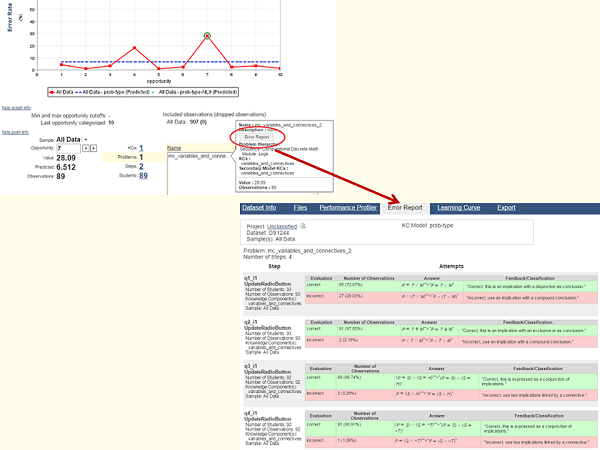
- Users can now quickly navigate from problem-specific information in a Learning Curve or Performance Profiler report directly to that problem in the Error Report; an "Error Report" button has been added to the tooltips. The Error Report includes information on the actual values students entered and the feedback received when working on the problem.
- In the Performance Profiler, if a secondary KC model is selected, the skills from the secondary model that are present in the problem are included in the problem info tooltip.

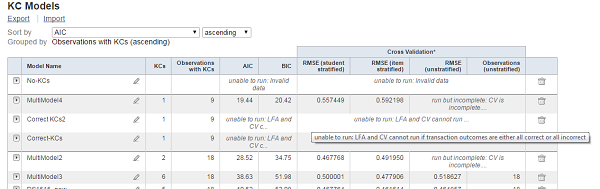
- If the Additive Factors Model (AFM) or Cross Validation (CV) algorithms fail or cannot be run, the reason is now available to the user as a tooltip. The tooltip is present when hovering over the status in the KC Models table. If you have a follow-up questions, remember that you can always send email to datashop-help.
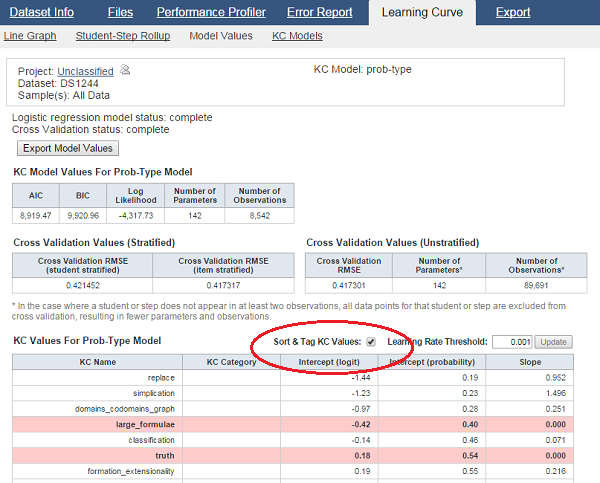
- Users can now sort the skills in a particular KC model to indicate learning difficulty. By sorting the KC model skills by intercept and then tagging those for which the slope is below some threshold, users can easily identify skills that may be misspecified and should be split into multiple skills. See the DataShop Tutorial videos on how to change the skills and test the result of that change. This sorting feature is available on the "Model Values" tab of the Learning Curve page.
- The Cross Validation calculation was modified to provide more statistically valid results. The new calculation computes an average over 20 runs in determining the root mean squared error (RMSE).
Bug fixes
- The Student-Step Export was updated to print only a single predicted-error-rate value for steps with multiple skills, as the values are always the same.
- The Help pages for the Additive Factors Modeling (AFM) have been updated to indicate that DataShop implements a compensatory sum across all Knowledge Components when there are multiple KCs assigned to a single step.
- The KC Model Import was fixed to ensure that invalid characters cannot be used in the model name not only during initial model import, but also in the dialog box that comes up when a duplicate name is detected.